Learning objectives:
- Reverse engineering Linux ELF binaries using ''objdump''.
- Finding ''dlopen(3)'' calls using ''strace''.
- Crafting a patch using ''nasm''.
- Binary patching with ''dd'', including potential pitfalls.
- Some notes on symbols and (C++) name manglings.
- Inspecting the binary representation of a C++ constructor.
.::::::::.
::::::::::::.
:::::::::::::
::::::::::::
::::::::::'
:::::::::'
:::'''::::::.
::::::::::.
000000 .:. :::::::::::.
00000000000 ':::. ::-:::::::: ::.
00000000000000 ':::::'::::::::: '::
0000000000000000 '' :::::::::''
10000000000000000 ::::::::::
11000000000000000 :::::::::::
11100000000000000 .:::::::::::.
11110000000000000 :::::::::::'
11111000000000000 .::::::::'
11111100000000000 ''':: ::
11111110000000000 .:: ::: ________
11111111000000000 ::_____':: %#
11111111000000000 ________ :: % ':: %#/
11111111100000000 ______/ %#/ :: #/ .::: %#/
11111111110000000 _____ / %#/ %#/ .:::' .:::%#/ %
11111111111000000 _____ / %#/ %#/ %#/ "./ .%#/ %#/
11111111111000000 _____ / .%#/ .%#/ %#/ .%#/ %#/ %#/
1111111111100000 %#/ %#/ .%#/ .%#/ .%#/ %#/ .%#/ %#/
1111111111100000 %#/ %#/ .%#/ %#/ .%#/ .%#/ %#/ %#/
11111111110000 %#/ %#/ .%#/ .%#/ %#/ .%#/ .%#/ %#/
1111111110000 #/ %#/ %#/ %#/ %#/ %#/ %#/ %#/
===[ Hyphens Everywhere ]~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
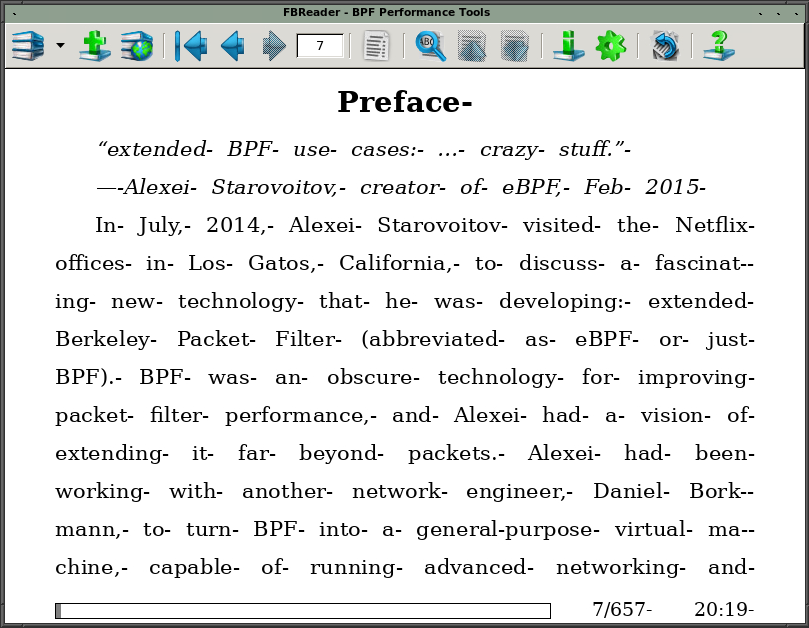
Debian FBReader has been a persistent thorn in my side. Its longstanding bug
causes hyphens to appear after each word, not just within ebook texts, but also
in the status bar and help pages:
 The first reasonable step is always to start with research, it could be a known
bug and someone has already found a solution. If we search for ''fbreader
hyphens bug'', we'll find that there is a relevant bug report from 2022 [ref1]:
Most of the time, fbreader draws hyphens after each word in any book including
its built-in help page. IIRC this started after switching to GTK. I cannot
find any useful patterns in reproducibility, or guess why does it happen (I
also tried looking at lsof and the config dir and check and change the app
settings). I can reproduce it on two testing/sid systems, including one with
an empty config.
Luckily for us, in the same thread there is a solution to the problem from
Siarhei Abmiotka [ref2] (good work!). The fix is straightforward: we just need
to add the missing initialization of ''flags''. Here is the complete patch:
-----------------------------------[ patch ]-----------------------------------
--- fbreader.orig/zlibrary/ui/src/gtk/view/ZLGtkPaintContext.cpp
+++ fbreader/zlibrary/ui/src/gtk/view/ZLGtkPaintContext.cpp
@@ -54,6 +54,7 @@ ZLGtkPaintContext::ZLGtkPaintContext() {
myFontDescription = 0;
myAnalysis.lang_engine = 0;
myAnalysis.level = 0;
+ myAnalysis.flags = 0;
myAnalysis.language = 0;
myAnalysis.extra_attrs = 0;
myString = pango_glyph_string_new();
-------------------------------------------------------------------------------
The primary issue is that the instantiation of ''myAnalysis'' is not
initialized with zeros by default, resulting in anything not explicitly set to
a value containing "random" garbage. In ''flags'', this leads to "the
hyphening" being frequently activated.
We could end here and patch the source file, build it, and start using the
fixed version of FBReader. But going through the FBReader's build process is a
tedious journey of failing dependencies and fixing broken code. I propose a far
more entertaining approach. What if we patch the binary? It's just one
initialization, so how hard could it be?
===[ Symbolism! ]~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Before we delve into binary hacking, we need to know a few things about
symbols. Simply put, a symbol is an alias for an address in a binary program.
For instance, if the ''printf'' function starts at address ''0x12540'', when
the linker encounters a reference to the ''printf'' symbol, it knows exactly
where to fix the call -- at that very address ''0x12540''.
In ELF binaries, symbols are stored in simple tables containing properties such
as name, offset, size, and more. During the build process, a program typically
uses one symbol table. This table is often removed (stripped) after the build
to reduce the binary's size (this operation is typically done by the ''strip''
command when build finishes).
In addition to the symbol table used for build, a library typically has a
second symbol table that contains information about the symbols it exports.
This table is crucial for the dynamic linker when loading a binary into memory,
as it enables the linker to resolve external references. For instance, the
dynamic symbol table of the C standard library (libc) contains symbols such as
''printf''. When mapping out a program and its libraries into memory, the
linker also populates special tables such as PLT (Procedure Linkage Table) and
GOT (Global Offset Table) with the addresses of the symbols referenced in the
code. This enables the code to know where to jump when calling a symbol. The
dynamic symbol table is essential for working libraries and is almost never
stripped (btw, it should be a red flag when the table is missing).
(ELF structure, relocations, linking and loading are beyond the scope of this
article. For those interested in learning more, please refer to [ref3]
[ref4] [ref5] for further details.)
Let's get practical and explore the exported symbols from libc using
''objdump'' from the ''binutils'' package [ref6]. (''objdump'' is an
incredibly useful tool that lets us analyze symbols and disassemble code. This
makes it surprisingly a great choice for quick reverse engineering on the Linux
command line.)
$ objdump --dynamic-syms /lib/x86_64-linux-gnu/libc.so.6
...
000000000007dbf0 w DF .text 000000000000010f GLIBC_2.2.5 fgetc
000000000009ba30 g DF .text 0000000000000073 GLIBC_2.2.5 envz_strip
^ ^ ^ ^ ^
| | | | |
offset symbol type section size symbol name
Most of the time, all we need are symbol names. The extra information, like
offset and size, are useful when manually navigating through a binary, but we
don't need it here, as we'll be working exclusively with symbols.
(For more details, please refer to the description of ''objdump --syms'' in
[ref6], the documentation is actually pretty good.)
===[ Name Mangling ]~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Some programming languages, such as C++, Go, and Rust, encode names of
functions, classes, structures, etc. because symbol names might collide. This
process is called name mangling. A great example of name collision is function
overloading in C++. Let's look at this simple example:
---------------------------------[ test.cpp ]----------------------------------
int func () { return 1; }
int func (int i, char c) { return 2; }
int main (int i, char **a) { return 0; }
-------------------------------------------------------------------------------
If compilers didn't perform name mangling, code would generate two symbols with
the same name, ''func'', but with completely different behavior. The linker
would be utterly confused about which function to use in each object file.
Therefore, the compiler takes all function definitions, including their
arguments and return values, and encodes them so that they have a unique name.
When we compile the source code above, we get a binary with two mangled
symbols:
$ g++ test.cpp -o ./test
$ objdump --syms ./test | grep 'func'
0000000000001129 g F .text 000000000000000b _Z4funcv
0000000000001134 g F .text 0000000000000011 _Z4funcic
As we can see, the symbols are unique but strange-looking. We can still see the
name ''func'' but it also has mysterious prefixes and suffixes. Name mangling
follows certain rules [ref7], although unfortunately, it is not standardized
(intentionally [ref8] [ref21]) and the output can differ even between compilers
of the same language (see [ref9] for different C++ mangling outputs). Here is a
sample illustration of the GNU C compiler's symbol mangling:
.-- mangling prefix '_Z'
| .-- func name .---- complete object constructor 'C1'
| | | .--- no arguments (void)
| | /| |
v v vv v
_ZN17ZLGtkPaintContextC1Ev --> ZLGtkPaintContext::ZLGtkPaintContext()
^^ ^
|| '-- end of nested-name
|'--- name length '17'
'--- beginning of nested-name
===[ Objdump Demangling ]~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Like most reverse engineering tools, objdump can automatically demangle
symbols. This is super cool! Remember the patch from the beginning? From it, we
know that the source code is written in C++ (the ''.cpp'' suffix is a good
indicator). That means the symbol names are mangled.
Before we use objdump on fbreader, let's see how the output looks for a C++
library like ''libstdc++.so'':
1. Raw symbol names:
$ objdump --dynamic-syms /lib/x86_64-linux-gnu/libstdc++.so.6 \
| grep -m 4 '\.text' \
| sed -r 's/^.*GLIBC[^ ]+ //'
_ZNKSbIwSt11char_traitsIwESaIwEE8capacityEv
_ZNSsC1Ev
_ZNSt7__cxx1112basic_stringIwSt11char_traitsIwESaIwEE10_M_disposeEv
_ZNSt9money_getIcSt19istreambuf_iteratorIcSt11char_traitsIcEEED0Ev
2. Demangled symbol names:
$ objdump --dynamic-syms --demangle /lib/x86_64-linux-gnu/libstdc++.so.6 \
| grep -m 4 '\.text' \
| sed -r 's/^.*GLIBC[^ ]+ //'
std::basic_string, std::allocator >::capacity() const
std::basic_string, std::allocator >::basic_string()
std::__cxx11::basic_string, std::allocator >::_M_dispose()
std::money_get > >::~money_get()
Excellent! Now we can look for the exact name, which in our case would be
''ZLGtkPaintContext::ZLGtkPaintContext()''. So let's finally find that damn
symbol and its code!
(NOTE: We could try to encode the name by hand and search for the mangled
symbol, but it's hard to do it correctly. For example, the symbol name
''ZLGtkPaintContext::ZLGtkPaintContext()'' will probably be encoded by GCC as
''_ZN17ZLGtkPaintContextC1Ev'', but we don't want to search for it like that,
as it can result in a false negative if the name is encoded differently.)
===[ Finding The Executable ]~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
The typical places where the symbol could be located are:
1. The ''fbreader'' binary itself.
2. Libraries that the ''fbreader'' binary uses.
3. Plugins that are loaded on-the-fly by mechanisms like ''dlopen'' [ref10].
(Btw, these plugins are just shared objects/libraries that haven't been loaded
yet when the program starts.)
Let's see what's waiting for us in the ''fbreader'' binary:
$ objdump --syms --demangle /usr/bin/fbreader
SYMBOL TABLE:
no symbols
Well, if it were that easy, I wouldn't be writing this article. If you're
familiar with Linux binaries, this isn't surprising -- Linux distributions'
binaries are typically stripped of symbols, after all. Before we fall into
the rabbit hole of searching for patterns in the fbreader binary, let's take a
closer look at the libraries involved (especially since the patch is in a path
starting with ''fbreader/zlibrary/...'').
One way to figure out what libraries fbreader depends on is to use the ''ldd''
command. This utility reads the dynamic section of an ELF binary and
recursively determines all the linked libraries:
$ ldd /usr/bin/fbreader
libstdc++.so.6 => /lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007fcf1f200000)
libzltext.so.0.13 => /lib/libzltext.so.0.13 (0x00007fcf1f6ac000)
libzlcore.so.0.13 => /lib/libzlcore.so.0.13 (0x00007fcf1f5eb000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fcf1f01f000)
...
Let's make a one-liner that reads all the libraries, lists their symbols, and
searches for the ''ZLGtkPaintContext'' symbol:
$ ldd /usr/bin/fbreader \
| awk '{print $3}' \
| xargs -I {} objdump --demangle --dynamic-syms {} \
| grep ZLGtkPaintContext
Absolutely muffin! What the hack?!
===[ Dlopen ]~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
It is still possible that the symbol is loaded dynamically via ''dlopen''. The
''dlopen(3)'' function [ref10] is often used to load dynamic shared objects
(aka shared library, aka plugins, aka addons).
The easiest way to determine if a program uses ''dlopen'' is to ''strace'' it.
We won't directly see the ''dlopen'' call, as it's not a syscall, but rather a
function from the ''libc.so'' library (historically, it was within the dynamic
linker library ''libdl.so''). What ''dlopen'' does is open a library (shared
object), map it to memory, and initialize it. Therefore, if we strace such a
program, we should see two syscalls: ''open(2)'' and ''mmap(2)''. Knowing this,
we can trace only for the ''open(2)'' syscalls (''-e trace=open,openat'') and
ask for a stack trace (''-k''). This should give us a clue if it's indeed an
instance of ''dlopen'' being called:
$ strace -f -e trace=open,openat -k -o ./strace.out /usr/bin/fbreader
$ less ./strace.out
...
openat(AT_FDCWD, "/usr/lib/zlibrary/ui/zlui-gtk.so", O_RDONLY|O_CLOEXEC) = 3
...
> /usr/lib/x86_64-linux-gnu/libc.so.6(dlopen+0x69) [0x854e9]
...
> /usr/bin/FBReader() [0x344da]
...
NOTE: Ironically, FBReader actually printed this to the console: ''loading
/usr/lib/zlibrary/ui/zlui-gtk.so''.
Let's investigate further by searching for the desired
''ZLGtkPaintContext::ZLGtkPaintContext'' symbol within the ''zlui-gtk.so''
shared object:
(Remember, the symbol names reside in the ELF's dynamic section. And the binary
was compiled with a C++ compiler, so we'll need to demangle all symbols to
identify the correct one.)
$ objdump --demangle --dynamic-syms /usr/lib/zlibrary/ui/zlui-gtk.so \
| grep -o '\:
26b90: 53 push rbx
26b91: 48 89 fb mov rbx,rdi
26b94: e8 77 33 ff ff call 19f10
...
26c5c: c3 ret
Great! Now we know *where* to hack, next we need to find out *what* exactly we
are hacking.
===[ C++ Constructor ]~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Let's quickly recap the patch:
@@ -54,6 +54,7 @@ ZLGtkPaintContext::ZLGtkPaintContext() {
+ myAnalysis.flags = 0;
What we ultimately aim to achieve is initializing ''myAnalysis.flags'' to zero.
To do so, we need to find a location where we can access the ''myAnalysis''
object. In C++ classes, this typically occurs in the constructor, as it's where
member objects are initialized. (This conclusion is also supported by the
patch, which suggests that both the object name and method names are
identical.)
Let's look at the code of the ''ZLGtkPaintContext::ZLGtkPaintContext'' symbol
(the constructor):
---------------[ ZLGtkPaintContext::ZLGtkPaintContext()@@Base ]----------------
0000000000026b90 :
26b90: 53 push rbx
26b91: 48 89 fb mov rbx,rdi
26b94: e8 77 33 ff ff call 19f10
26b99: 48 8b 05 68 03 01 00 mov rax,QWORD PTR [rip+0x10368]
26ba0: c6 83 8a 00 00 00 00 mov BYTE PTR [rbx+0x8a],0x0
26ba7: 48 c7 83 a0 00 00 00 mov QWORD PTR [rbx+0xa0],0x0
26bae: 00 00 00 00
26bb2: 48 83 c0 10 add rax,0x10
26bb6: 48 c7 43 20 00 00 00 mov QWORD PTR [rbx+0x20],0x0
26bbd: 00
26bbe: 48 89 03 mov QWORD PTR [rbx],rax
26bc1: 31 c0 xor eax,eax
26bc3: 66 89 83 88 00 00 00 mov WORD PTR [rbx+0x88],ax
26bca: 48 c7 83 a8 00 00 00 mov QWORD PTR [rbx+0xa8],0x0
26bd1: 00 00 00 00
26bd5: 48 c7 83 b0 00 00 00 mov QWORD PTR [rbx+0xb0],0x0
26bdc: 00 00 00 00
26be0: 48 c7 43 28 00 00 00 mov QWORD PTR [rbx+0x28],0x0
26be7: 00
26be8: 48 c7 43 30 00 00 00 mov QWORD PTR [rbx+0x30],0x0
26bef: 00
26bf0: 48 c7 43 38 00 00 00 mov QWORD PTR [rbx+0x38],0x0
26bf7: 00
26bf8: 48 c7 43 48 00 00 00 mov QWORD PTR [rbx+0x48],0x0
26bff: 00
26c00: c6 43 58 00 mov BYTE PTR [rbx+0x58],0x0
26c04: 48 c7 43 60 00 00 00 mov QWORD PTR [rbx+0x60],0x0
26c0b: 00
26c0c: 48 c7 43 68 00 00 00 mov QWORD PTR [rbx+0x68],0x0
26c13: 00
26c14: e8 d7 2b ff ff call 197f0
26c19: 48 c7 43 78 00 00 00 mov QWORD PTR [rbx+0x78],0x0
26c20: 00
26c21: 48 89 43 70 mov QWORD PTR [rbx+0x70],rax
26c25: 48 c7 83 80 00 00 00 mov QWORD PTR [rbx+0x80],0x0
26c2c: 00 00 00 00
26c30: 48 c7 83 90 00 00 00 mov QWORD PTR [rbx+0x90],0x0
26c37: 00 00 00 00
26c3b: 48 c7 83 98 00 00 00 mov QWORD PTR [rbx+0x98],0x0
26c42: 00 00 00 00
26c46: 48 c7 83 b8 00 00 00 mov QWORD PTR [rbx+0xb8],0xffffffffffffffff
26c4d: ff ff ff ff
26c51: c7 83 c0 00 00 00 00 mov DWORD PTR [rbx+0xc0],0x0
26c58: 00 00 00
26c5b: 5b pop rbx
26c5c: c3 ret
-------------------------------------------------------------------------------
Nice! And the code isn't too large, we can easily analyze it. At first glance,
there is an emerging pattern: most instructions set zero to memory locations at
''rbx'' plus some offset. This looks like the initialization we're searching
for. Now, we need to identify where the ''myAnalysis'' instance begins...
Alternatively, we could find all missing initializations and set them to zero.
(I believe it's safe to assume that fbreader is not the OpenSSH [ref11] [ref12]
and that we can safely initialize all objects in the constructor.)
Locating uninitialized bytes is kinda straightforward. To begin, we collect all
''mov'' instructions that reference ''rbx'', then sort them by offset to
identify any gaps in the sequence. By considering the size of each data type,
we can pinpoint which offset is missing.
Before we start, here is a quick data type reference ''objdump'' is using:
NAME NUM_BYTES
-----------------
QWORD 8
DWORD 4
WORD 2
BYTE 1
Let's run the following command, which lists all ''rbx'' (i.e., the ''this->''
keyword) assignments, and construct a table with missing initializations:
objdump -M intel --disassemble='ZLGtkPaintContext::ZLGtkPaintContext()' \
--demangle /usr/lib/zlibrary/ui/zlui-gtk.so \
| grep -Eo '\<[A-Z]+ PTR \[rbx.*' \
| sort -t + -k 2 \
| vim -
-----------------------[ Table: Missing initialization ]-----------------------
QWORD PTR [rbx],rax
# 24 uninitialized bytes
QWORD PTR [rbx+0x20],0x0
QWORD PTR [rbx+0x28],0x0
QWORD PTR [rbx+0x30],0x0
QWORD PTR [rbx+0x38],0x0
# 8 uninitialized bytes
QWORD PTR [rbx+0x48],0x0
# 8 uninitialized bytes
BYTE PTR [rbx+0x58],0x0
# 7 uninitialized bytes
QWORD PTR [rbx+0x60],0x0
QWORD PTR [rbx+0x68],0x0
QWORD PTR [rbx+0x70],rax
QWORD PTR [rbx+0x78],0x0
QWORD PTR [rbx+0x80],0x0
WORD PTR [rbx+0x88],ax
BYTE PTR [rbx+0x8a],0x0
# 5 uninitialized bytes
QWORD PTR [rbx+0x90],0x0
QWORD PTR [rbx+0x98],0x0
QWORD PTR [rbx+0xa0],0x0
QWORD PTR [rbx+0xa8],0x0
QWORD PTR [rbx+0xb0],0x0
QWORD PTR [rbx+0xb8],0xffffffffffffffff
DWORD PTR [rbx+0xc0],0x0
# (foreshadowing: 4 uninitialized bytes)
-------------------------------------------------------------------------------
Cool, cool. Most gaps can be computed simply by subtracting the offsets.
However, there remains one particular gap: how many bytes are after the last
''mov DWORD PTR [rbx+0xc0],0x0'' instruction? This could be either zero or
multiple bytes. The answer to this question lies in identifying the class
instantiation (allocation).
If we search for ''ZLGtkPaintContext::ZLGtkPaintContext'' and examine all
occurrences, we'll likely find the instantiation of the class. In my case, it
is in the ''ZLGtkLibraryImplementation::createContext'' method:
0000000000024620 :
24620: 41 54 push r12
24622: bf c8 00 00 00 mov edi,0xc8
24627: e8 d4 59 ff ff call 1a000
2462c: 49 89 c4 mov r12,rax
2462f: 48 89 c7 mov rdi,rax
24632: e8 39 5f ff ff call 1a570
24637: 4c 89 e0 mov rax,r12
2463a: 41 5c pop r12
2463c: c3 ret
The function initially allocates ''0xc8'' bytes, and the ''operator new'' will
return a pointer to heap memory. Subsequently, it calls the
''ZLGtkPaintContext::ZLGtkPaintContext()'' class constructor with the newly
allocated memory pointer as its first argument. (NOTE: In C++, the first
argument of any class method is always the address of the current object,
denoted by the keyword ''this''.)
Now that we know the ''ZLGtkPaintContext'' class uses overall 0xc8 bytes, and
the last initialized entry is at affset 0xc0 (which is ''DWORD'', or 4 bytes),
ww can perform simple algebra to determine how many potentially uninitialized
bytes are after ''rbx+0xc0'':
overall_size - last_rbx_offset + last_rbx_datatype_len =
= 0xc8 - 0xc0 + 4 =
= 4
Here is the table summarizing the intervals for the "missing" offsets:
...
QWORD PTR [rbx+0x70],rax ; 'rax' was set by the call
QWORD PTR [rbx+0xb8],0xffffffffffffffff
Rewrites could look like this:
--------------------------[ patch_protoype_01.nasm ]---------------------------
xor eax, eax ; zero out RAX
mov QWORD [rbx+0x08], rax ; offset 0x08-0x10
mov QWORD [rbx+0x10], rax ; offset 0x10-0x18
mov QWORD [rbx+0x18], rax ; offset 0x18-0x20
mov QWORD [rbx+0x40], rax ; offset 0x40-0x48
mov QWORD [rbx+0x50], rax ; offset 0x50-0x58
mov QWORD [rbx+0x58], rax ; offset 0x58-0x60 <-- [1]
; call 197f0
; WORD PTR [rbx+0x88],ax
xor eax, eax ; zero out RAX again, it might contain a value
mov DWORD [rbx+0x8a], rax ; offset 0x8a-0x90 <-- [2]
mov QWORD [rbx+0xc0], rax ; offset 0xc0-0xc8 <-- [1]
-------------------------------------------------------------------------------
In certain situations, we can combine multiple values into a single instruction
that utilizes a large bit range, as demonstrated in [1]. However, in some
cases, like in [2], we need be careful, and avoid writing memory before it
(''[rbx+0x88]'') because it holds the return value of a function (''ax'').
And we can take it even further by leveraging features of the x86 instruction
set and the original code to our advantage. We could prototype a kind of loop
that will effectively zero out the entire allocated memory. The only concern we
should have is ensuring that we avoid those non-zero assignments we previously
discovered.
I have something like this in mind:
--------------------------[ patch_protoype_02.nasm ]---------------------------
BITS 64
push rcx ; Save all registers we are working with
push rdi
push rax
mov ecx, 0xc0 / 8 ; Counter: size of memory divided by QWORD length
xor eax, eax ; Zero out RAX, we'll use it as the zero value
mov rdi, rbx ; RDI is a memory pointer 'stosq' is writing to
rep stosq ; Rewrite memory at 'RDI+RCX' with value of 'RAX'
pop rax ; Restore all registers we where working with
pop rdi
pop rcx
-------------------------------------------------------------------------------
NOTE: ''stosq'' stores quadword from RAX at address RDI [ref14] (in our
example, this means 8 bytes of zeroes). ''rep'' is an instruction prefix that
repeats a string instruction the number of times specified in RCX (''rep'' can
be used only with specific instructions -- see [ref15]).
When built, the binary code has a size of 19 bytes:
$ nasm -O 0 -f bin patch_protoype_01.nasm -o patch_protoype_01
$ wc -c < a.bin
19
However, this isn't good enough for me. I'd like to place it near the beginning
(specifically at the address ''26ba0''), so that it doesn't overwrite the later
assignments. The code I want to replace is:
26ba0: c6 83 8a 00 00 00 00 mov BYTE PTR [rbx+0x8a],0x0
26ba7: 48 c7 83 a0 00 00 00 mov QWORD PTR [rbx+0xa0],0x0
26bae: 00 00 00 00
Unfortunately, these instructions together take up 18 bytes in total. Since our
prototype code has an extra byte, we would actually be overflowing. This cannot
happen!
There are two widely used techniques to optimize the size of a binary:
1. Using smaller opcodes. For example, the instruction ''mov ecx, 0xc0 / 8'' is
represented as ''B918000000'' in binary and occupies 5 bytes. Paradoxically, by
splitting it into two instructions, we can make it more compact: ''xor ecx,ecx;
mov cl,0xc0 / 8'', which results in the binary code ''31c9b118''. And there we
have the one byte we need.
2. Oooor we can exploit the code to our advantage by identifying and removing
any unnecessary instructions that are not used within the function. For
instance, ''rdi'' is a callee-saved register that is only used once at the
beginning, where its value is stored into ''rbx'', which serves as the ''this''
pointer. In this case, we can eliminate at least these three instructions:
push rdi ; no need to save it, it's not used
pop rdi ; and no need to restore it either
mov rdi, rbx ; moreover, RDI has the same value as RBX
Optimized code would look like this:
--------------------------[ patch_protoype_02.nasm ]---------------------------
BITS 64
push rcx ; Save all registers we are working with
push rax
mov ecx, 0xc0 / 8 ; Allocated memory divided by QWORD length
xor eax, eax ; Zero out RAX as we'll use it as the value
rep stosq ; Rewrite memory at 'rdi+rcx' with the value in 'rax'.
pop rax ; Restore all registers we where working with
pop rcx
-------------------------------------------------------------------------------
Now it has only 14 bytes:
$ nasm -O 0 -f bin patch_protoype_02.nasm -o patch_protoype_02
$ wc -c < patch_protoype_02
14
This is cool, but now it's way too small (or still not small enough), so we
have to pad the rest. There are ''18 - 14 = 4'' bytes to pad. We could use four
''nop'' instructions and be done with it, buuuut there are multi-byte NOP
instructions [ref16] that can also be used. Unfortunately, NASM doesn't
properly support them, therefore we need to create a correct sequence of bytes:
db 0x0F, 0x1F, 0x40, 0x00
(I won't deny it, this code does look much 1337er!)
I would likely attempt to further optimize it or simply go with the first
technique and create an 18-byte-sized binary code, but playtime's over! Let's
patch!
===[ Patching ]~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
It's time to roll up our sleeves and get started. We don't need any fancy tools
to get the job done. Patching can be accomplished with just "good" old ''dd''
[ref17].
We'll need to be precise here. In addition to rewriting bytes at the correct
offset and rewriting only 18 bytes, we must also ensure that the file isn't
truncated. ''dd'' is a very useful tool, but it's definitely not the most
user-friendly. (No wonder, it's from 1974 [ref18].)
Rewriting bytes on the exact position using ''dd'' can be tricky. The
old-school approach is to set the output block size (''obs'') to 1, which seeks
to the correct position but writes input one byte at a time (i.e., for every
byte, the ''write(2)'' syscall is called). While this approach is inefficient,
it's negligible for small inputs. Newer versions of ''dd'' offer the "byte"
suffix (''B'') for seek/skip options, allowing us to write commands like:
''dd if=i of=o skip=7B'' without sacrificing block size.
Let's take ''patch_protoype_01.nasm'' and craft the final code that we will
inject:
------------------------------[ inject_me.nasm ]-------------------------------
BITS 64
push rcx ; Save all registers we are working with
push rax
mov ecx, 0xc0 / 8 ; Allocated memory divided by the QWORD length
xor eax, eax ; Zero out RAX, we'll use it as the zero value
rep stosq ; Rewrite memory at RDI+RCX with the value in RAX
pop rax ; Restore all registers we where working with
pop rcx
db 0x0F, 0x1F, 0x40, 0x00 ; 4-byte NOP
-------------------------------------------------------------------------------
Build it:
$ nasm -O 0 -f bin inject_me.nasm -o inject_me
$ xxd -ps inject_me
5150b9c000000031c0f348ab58590f1f4000
$ wc -c < inject_me
18
And finally, let's inject the binary patch into the library at the offset
''0x26ba0'':
$ cp -a /usr/lib/zlibrary/ui/zlui-gtk.so .
$ dd if=inject_me of=zlui-gtk.so seek=$((0x26ba0)) obs=1 conv=notrunc
NOTE: The ''$((...))'' construct is shell math evaluation. which allows for the
quick conversion of hexadecimal numbers to decimal values and computation of
offsets on-the-fly, eliminating the need to evaluating it beforehand.
After patching, we should always verify that the resulting binary looks
correct:
$ objdump -M intel --disassemble='ZLGtkPaintContext::ZLGtkPaintContext()' \
--demangle ./zlui-gtk.so
...
26b99: 48 8b 05 68 03 01 00 mov rax,QWORD PTR [rip+0x10368]
26ba0: 51 push rcx
26ba1: 50 push rax
26ba2: b9 c0 00 00 00 mov ecx,0xc0
26ba7: 31 c0 xor eax,eax
26ba9: f3 48 ab rep stos QWORD PTR es:[rdi],rax
26bac: 58 pop rax
26bad: 59 pop rcx
26bae: 0f 1f 40 00 nop DWORD PTR [rax+0x0]
26bb2: 48 83 c0 10 add rax,0x10
...
Oh yeah! Everything looks good. Before we run our test, we need to replace the
original ''/usr/lib/zlibrary/ui/zlui-gtk.so'' with the modified one. Setting
''LD_LIBRARY_PATH'' has no effect because the path to the plugins is hardcoded
into the binary. (Try searching for the ''/usr/lib'' pattern within the
''/usr/lib/libzlcore.so'' library, and then use objdump to find the resulting
offset. You might see something like ''movabs rax,0x62696c2f7273752f'', which
represents the ''/usr/lib'' string in big-endian hexadecimal format, followed
by the loading of the ''/zlibrary/ui'' string from the ''.data'' section.)
# mv /usr/lib/zlibrary/ui/zlui-gtk.so /usr/lib/zlibrary/ui/zlui-gtk.so.OLD
# cp -a zlui-gtk.so /usr/lib/zlibrary/ui/zlui-gtk.so
$ fbreader bpf_performance_tools.epub
The first reasonable step is always to start with research, it could be a known
bug and someone has already found a solution. If we search for ''fbreader
hyphens bug'', we'll find that there is a relevant bug report from 2022 [ref1]:
Most of the time, fbreader draws hyphens after each word in any book including
its built-in help page. IIRC this started after switching to GTK. I cannot
find any useful patterns in reproducibility, or guess why does it happen (I
also tried looking at lsof and the config dir and check and change the app
settings). I can reproduce it on two testing/sid systems, including one with
an empty config.
Luckily for us, in the same thread there is a solution to the problem from
Siarhei Abmiotka [ref2] (good work!). The fix is straightforward: we just need
to add the missing initialization of ''flags''. Here is the complete patch:
-----------------------------------[ patch ]-----------------------------------
--- fbreader.orig/zlibrary/ui/src/gtk/view/ZLGtkPaintContext.cpp
+++ fbreader/zlibrary/ui/src/gtk/view/ZLGtkPaintContext.cpp
@@ -54,6 +54,7 @@ ZLGtkPaintContext::ZLGtkPaintContext() {
myFontDescription = 0;
myAnalysis.lang_engine = 0;
myAnalysis.level = 0;
+ myAnalysis.flags = 0;
myAnalysis.language = 0;
myAnalysis.extra_attrs = 0;
myString = pango_glyph_string_new();
-------------------------------------------------------------------------------
The primary issue is that the instantiation of ''myAnalysis'' is not
initialized with zeros by default, resulting in anything not explicitly set to
a value containing "random" garbage. In ''flags'', this leads to "the
hyphening" being frequently activated.
We could end here and patch the source file, build it, and start using the
fixed version of FBReader. But going through the FBReader's build process is a
tedious journey of failing dependencies and fixing broken code. I propose a far
more entertaining approach. What if we patch the binary? It's just one
initialization, so how hard could it be?
===[ Symbolism! ]~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Before we delve into binary hacking, we need to know a few things about
symbols. Simply put, a symbol is an alias for an address in a binary program.
For instance, if the ''printf'' function starts at address ''0x12540'', when
the linker encounters a reference to the ''printf'' symbol, it knows exactly
where to fix the call -- at that very address ''0x12540''.
In ELF binaries, symbols are stored in simple tables containing properties such
as name, offset, size, and more. During the build process, a program typically
uses one symbol table. This table is often removed (stripped) after the build
to reduce the binary's size (this operation is typically done by the ''strip''
command when build finishes).
In addition to the symbol table used for build, a library typically has a
second symbol table that contains information about the symbols it exports.
This table is crucial for the dynamic linker when loading a binary into memory,
as it enables the linker to resolve external references. For instance, the
dynamic symbol table of the C standard library (libc) contains symbols such as
''printf''. When mapping out a program and its libraries into memory, the
linker also populates special tables such as PLT (Procedure Linkage Table) and
GOT (Global Offset Table) with the addresses of the symbols referenced in the
code. This enables the code to know where to jump when calling a symbol. The
dynamic symbol table is essential for working libraries and is almost never
stripped (btw, it should be a red flag when the table is missing).
(ELF structure, relocations, linking and loading are beyond the scope of this
article. For those interested in learning more, please refer to [ref3]
[ref4] [ref5] for further details.)
Let's get practical and explore the exported symbols from libc using
''objdump'' from the ''binutils'' package [ref6]. (''objdump'' is an
incredibly useful tool that lets us analyze symbols and disassemble code. This
makes it surprisingly a great choice for quick reverse engineering on the Linux
command line.)
$ objdump --dynamic-syms /lib/x86_64-linux-gnu/libc.so.6
...
000000000007dbf0 w DF .text 000000000000010f GLIBC_2.2.5 fgetc
000000000009ba30 g DF .text 0000000000000073 GLIBC_2.2.5 envz_strip
^ ^ ^ ^ ^
| | | | |
offset symbol type section size symbol name
Most of the time, all we need are symbol names. The extra information, like
offset and size, are useful when manually navigating through a binary, but we
don't need it here, as we'll be working exclusively with symbols.
(For more details, please refer to the description of ''objdump --syms'' in
[ref6], the documentation is actually pretty good.)
===[ Name Mangling ]~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Some programming languages, such as C++, Go, and Rust, encode names of
functions, classes, structures, etc. because symbol names might collide. This
process is called name mangling. A great example of name collision is function
overloading in C++. Let's look at this simple example:
---------------------------------[ test.cpp ]----------------------------------
int func () { return 1; }
int func (int i, char c) { return 2; }
int main (int i, char **a) { return 0; }
-------------------------------------------------------------------------------
If compilers didn't perform name mangling, code would generate two symbols with
the same name, ''func'', but with completely different behavior. The linker
would be utterly confused about which function to use in each object file.
Therefore, the compiler takes all function definitions, including their
arguments and return values, and encodes them so that they have a unique name.
When we compile the source code above, we get a binary with two mangled
symbols:
$ g++ test.cpp -o ./test
$ objdump --syms ./test | grep 'func'
0000000000001129 g F .text 000000000000000b _Z4funcv
0000000000001134 g F .text 0000000000000011 _Z4funcic
As we can see, the symbols are unique but strange-looking. We can still see the
name ''func'' but it also has mysterious prefixes and suffixes. Name mangling
follows certain rules [ref7], although unfortunately, it is not standardized
(intentionally [ref8] [ref21]) and the output can differ even between compilers
of the same language (see [ref9] for different C++ mangling outputs). Here is a
sample illustration of the GNU C compiler's symbol mangling:
.-- mangling prefix '_Z'
| .-- func name .---- complete object constructor 'C1'
| | | .--- no arguments (void)
| | /| |
v v vv v
_ZN17ZLGtkPaintContextC1Ev --> ZLGtkPaintContext::ZLGtkPaintContext()
^^ ^
|| '-- end of nested-name
|'--- name length '17'
'--- beginning of nested-name
===[ Objdump Demangling ]~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Like most reverse engineering tools, objdump can automatically demangle
symbols. This is super cool! Remember the patch from the beginning? From it, we
know that the source code is written in C++ (the ''.cpp'' suffix is a good
indicator). That means the symbol names are mangled.
Before we use objdump on fbreader, let's see how the output looks for a C++
library like ''libstdc++.so'':
1. Raw symbol names:
$ objdump --dynamic-syms /lib/x86_64-linux-gnu/libstdc++.so.6 \
| grep -m 4 '\.text' \
| sed -r 's/^.*GLIBC[^ ]+ //'
_ZNKSbIwSt11char_traitsIwESaIwEE8capacityEv
_ZNSsC1Ev
_ZNSt7__cxx1112basic_stringIwSt11char_traitsIwESaIwEE10_M_disposeEv
_ZNSt9money_getIcSt19istreambuf_iteratorIcSt11char_traitsIcEEED0Ev
2. Demangled symbol names:
$ objdump --dynamic-syms --demangle /lib/x86_64-linux-gnu/libstdc++.so.6 \
| grep -m 4 '\.text' \
| sed -r 's/^.*GLIBC[^ ]+ //'
std::basic_string, std::allocator >::capacity() const
std::basic_string, std::allocator >::basic_string()
std::__cxx11::basic_string, std::allocator >::_M_dispose()
std::money_get > >::~money_get()
Excellent! Now we can look for the exact name, which in our case would be
''ZLGtkPaintContext::ZLGtkPaintContext()''. So let's finally find that damn
symbol and its code!
(NOTE: We could try to encode the name by hand and search for the mangled
symbol, but it's hard to do it correctly. For example, the symbol name
''ZLGtkPaintContext::ZLGtkPaintContext()'' will probably be encoded by GCC as
''_ZN17ZLGtkPaintContextC1Ev'', but we don't want to search for it like that,
as it can result in a false negative if the name is encoded differently.)
===[ Finding The Executable ]~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
The typical places where the symbol could be located are:
1. The ''fbreader'' binary itself.
2. Libraries that the ''fbreader'' binary uses.
3. Plugins that are loaded on-the-fly by mechanisms like ''dlopen'' [ref10].
(Btw, these plugins are just shared objects/libraries that haven't been loaded
yet when the program starts.)
Let's see what's waiting for us in the ''fbreader'' binary:
$ objdump --syms --demangle /usr/bin/fbreader
SYMBOL TABLE:
no symbols
Well, if it were that easy, I wouldn't be writing this article. If you're
familiar with Linux binaries, this isn't surprising -- Linux distributions'
binaries are typically stripped of symbols, after all. Before we fall into
the rabbit hole of searching for patterns in the fbreader binary, let's take a
closer look at the libraries involved (especially since the patch is in a path
starting with ''fbreader/zlibrary/...'').
One way to figure out what libraries fbreader depends on is to use the ''ldd''
command. This utility reads the dynamic section of an ELF binary and
recursively determines all the linked libraries:
$ ldd /usr/bin/fbreader
libstdc++.so.6 => /lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007fcf1f200000)
libzltext.so.0.13 => /lib/libzltext.so.0.13 (0x00007fcf1f6ac000)
libzlcore.so.0.13 => /lib/libzlcore.so.0.13 (0x00007fcf1f5eb000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fcf1f01f000)
...
Let's make a one-liner that reads all the libraries, lists their symbols, and
searches for the ''ZLGtkPaintContext'' symbol:
$ ldd /usr/bin/fbreader \
| awk '{print $3}' \
| xargs -I {} objdump --demangle --dynamic-syms {} \
| grep ZLGtkPaintContext
Absolutely muffin! What the hack?!
===[ Dlopen ]~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
It is still possible that the symbol is loaded dynamically via ''dlopen''. The
''dlopen(3)'' function [ref10] is often used to load dynamic shared objects
(aka shared library, aka plugins, aka addons).
The easiest way to determine if a program uses ''dlopen'' is to ''strace'' it.
We won't directly see the ''dlopen'' call, as it's not a syscall, but rather a
function from the ''libc.so'' library (historically, it was within the dynamic
linker library ''libdl.so''). What ''dlopen'' does is open a library (shared
object), map it to memory, and initialize it. Therefore, if we strace such a
program, we should see two syscalls: ''open(2)'' and ''mmap(2)''. Knowing this,
we can trace only for the ''open(2)'' syscalls (''-e trace=open,openat'') and
ask for a stack trace (''-k''). This should give us a clue if it's indeed an
instance of ''dlopen'' being called:
$ strace -f -e trace=open,openat -k -o ./strace.out /usr/bin/fbreader
$ less ./strace.out
...
openat(AT_FDCWD, "/usr/lib/zlibrary/ui/zlui-gtk.so", O_RDONLY|O_CLOEXEC) = 3
...
> /usr/lib/x86_64-linux-gnu/libc.so.6(dlopen+0x69) [0x854e9]
...
> /usr/bin/FBReader() [0x344da]
...
NOTE: Ironically, FBReader actually printed this to the console: ''loading
/usr/lib/zlibrary/ui/zlui-gtk.so''.
Let's investigate further by searching for the desired
''ZLGtkPaintContext::ZLGtkPaintContext'' symbol within the ''zlui-gtk.so''
shared object:
(Remember, the symbol names reside in the ELF's dynamic section. And the binary
was compiled with a C++ compiler, so we'll need to demangle all symbols to
identify the correct one.)
$ objdump --demangle --dynamic-syms /usr/lib/zlibrary/ui/zlui-gtk.so \
| grep -o '\:
26b90: 53 push rbx
26b91: 48 89 fb mov rbx,rdi
26b94: e8 77 33 ff ff call 19f10
...
26c5c: c3 ret
Great! Now we know *where* to hack, next we need to find out *what* exactly we
are hacking.
===[ C++ Constructor ]~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Let's quickly recap the patch:
@@ -54,6 +54,7 @@ ZLGtkPaintContext::ZLGtkPaintContext() {
+ myAnalysis.flags = 0;
What we ultimately aim to achieve is initializing ''myAnalysis.flags'' to zero.
To do so, we need to find a location where we can access the ''myAnalysis''
object. In C++ classes, this typically occurs in the constructor, as it's where
member objects are initialized. (This conclusion is also supported by the
patch, which suggests that both the object name and method names are
identical.)
Let's look at the code of the ''ZLGtkPaintContext::ZLGtkPaintContext'' symbol
(the constructor):
---------------[ ZLGtkPaintContext::ZLGtkPaintContext()@@Base ]----------------
0000000000026b90 :
26b90: 53 push rbx
26b91: 48 89 fb mov rbx,rdi
26b94: e8 77 33 ff ff call 19f10
26b99: 48 8b 05 68 03 01 00 mov rax,QWORD PTR [rip+0x10368]
26ba0: c6 83 8a 00 00 00 00 mov BYTE PTR [rbx+0x8a],0x0
26ba7: 48 c7 83 a0 00 00 00 mov QWORD PTR [rbx+0xa0],0x0
26bae: 00 00 00 00
26bb2: 48 83 c0 10 add rax,0x10
26bb6: 48 c7 43 20 00 00 00 mov QWORD PTR [rbx+0x20],0x0
26bbd: 00
26bbe: 48 89 03 mov QWORD PTR [rbx],rax
26bc1: 31 c0 xor eax,eax
26bc3: 66 89 83 88 00 00 00 mov WORD PTR [rbx+0x88],ax
26bca: 48 c7 83 a8 00 00 00 mov QWORD PTR [rbx+0xa8],0x0
26bd1: 00 00 00 00
26bd5: 48 c7 83 b0 00 00 00 mov QWORD PTR [rbx+0xb0],0x0
26bdc: 00 00 00 00
26be0: 48 c7 43 28 00 00 00 mov QWORD PTR [rbx+0x28],0x0
26be7: 00
26be8: 48 c7 43 30 00 00 00 mov QWORD PTR [rbx+0x30],0x0
26bef: 00
26bf0: 48 c7 43 38 00 00 00 mov QWORD PTR [rbx+0x38],0x0
26bf7: 00
26bf8: 48 c7 43 48 00 00 00 mov QWORD PTR [rbx+0x48],0x0
26bff: 00
26c00: c6 43 58 00 mov BYTE PTR [rbx+0x58],0x0
26c04: 48 c7 43 60 00 00 00 mov QWORD PTR [rbx+0x60],0x0
26c0b: 00
26c0c: 48 c7 43 68 00 00 00 mov QWORD PTR [rbx+0x68],0x0
26c13: 00
26c14: e8 d7 2b ff ff call 197f0
26c19: 48 c7 43 78 00 00 00 mov QWORD PTR [rbx+0x78],0x0
26c20: 00
26c21: 48 89 43 70 mov QWORD PTR [rbx+0x70],rax
26c25: 48 c7 83 80 00 00 00 mov QWORD PTR [rbx+0x80],0x0
26c2c: 00 00 00 00
26c30: 48 c7 83 90 00 00 00 mov QWORD PTR [rbx+0x90],0x0
26c37: 00 00 00 00
26c3b: 48 c7 83 98 00 00 00 mov QWORD PTR [rbx+0x98],0x0
26c42: 00 00 00 00
26c46: 48 c7 83 b8 00 00 00 mov QWORD PTR [rbx+0xb8],0xffffffffffffffff
26c4d: ff ff ff ff
26c51: c7 83 c0 00 00 00 00 mov DWORD PTR [rbx+0xc0],0x0
26c58: 00 00 00
26c5b: 5b pop rbx
26c5c: c3 ret
-------------------------------------------------------------------------------
Nice! And the code isn't too large, we can easily analyze it. At first glance,
there is an emerging pattern: most instructions set zero to memory locations at
''rbx'' plus some offset. This looks like the initialization we're searching
for. Now, we need to identify where the ''myAnalysis'' instance begins...
Alternatively, we could find all missing initializations and set them to zero.
(I believe it's safe to assume that fbreader is not the OpenSSH [ref11] [ref12]
and that we can safely initialize all objects in the constructor.)
Locating uninitialized bytes is kinda straightforward. To begin, we collect all
''mov'' instructions that reference ''rbx'', then sort them by offset to
identify any gaps in the sequence. By considering the size of each data type,
we can pinpoint which offset is missing.
Before we start, here is a quick data type reference ''objdump'' is using:
NAME NUM_BYTES
-----------------
QWORD 8
DWORD 4
WORD 2
BYTE 1
Let's run the following command, which lists all ''rbx'' (i.e., the ''this->''
keyword) assignments, and construct a table with missing initializations:
objdump -M intel --disassemble='ZLGtkPaintContext::ZLGtkPaintContext()' \
--demangle /usr/lib/zlibrary/ui/zlui-gtk.so \
| grep -Eo '\<[A-Z]+ PTR \[rbx.*' \
| sort -t + -k 2 \
| vim -
-----------------------[ Table: Missing initialization ]-----------------------
QWORD PTR [rbx],rax
# 24 uninitialized bytes
QWORD PTR [rbx+0x20],0x0
QWORD PTR [rbx+0x28],0x0
QWORD PTR [rbx+0x30],0x0
QWORD PTR [rbx+0x38],0x0
# 8 uninitialized bytes
QWORD PTR [rbx+0x48],0x0
# 8 uninitialized bytes
BYTE PTR [rbx+0x58],0x0
# 7 uninitialized bytes
QWORD PTR [rbx+0x60],0x0
QWORD PTR [rbx+0x68],0x0
QWORD PTR [rbx+0x70],rax
QWORD PTR [rbx+0x78],0x0
QWORD PTR [rbx+0x80],0x0
WORD PTR [rbx+0x88],ax
BYTE PTR [rbx+0x8a],0x0
# 5 uninitialized bytes
QWORD PTR [rbx+0x90],0x0
QWORD PTR [rbx+0x98],0x0
QWORD PTR [rbx+0xa0],0x0
QWORD PTR [rbx+0xa8],0x0
QWORD PTR [rbx+0xb0],0x0
QWORD PTR [rbx+0xb8],0xffffffffffffffff
DWORD PTR [rbx+0xc0],0x0
# (foreshadowing: 4 uninitialized bytes)
-------------------------------------------------------------------------------
Cool, cool. Most gaps can be computed simply by subtracting the offsets.
However, there remains one particular gap: how many bytes are after the last
''mov DWORD PTR [rbx+0xc0],0x0'' instruction? This could be either zero or
multiple bytes. The answer to this question lies in identifying the class
instantiation (allocation).
If we search for ''ZLGtkPaintContext::ZLGtkPaintContext'' and examine all
occurrences, we'll likely find the instantiation of the class. In my case, it
is in the ''ZLGtkLibraryImplementation::createContext'' method:
0000000000024620 :
24620: 41 54 push r12
24622: bf c8 00 00 00 mov edi,0xc8
24627: e8 d4 59 ff ff call 1a000
2462c: 49 89 c4 mov r12,rax
2462f: 48 89 c7 mov rdi,rax
24632: e8 39 5f ff ff call 1a570
24637: 4c 89 e0 mov rax,r12
2463a: 41 5c pop r12
2463c: c3 ret
The function initially allocates ''0xc8'' bytes, and the ''operator new'' will
return a pointer to heap memory. Subsequently, it calls the
''ZLGtkPaintContext::ZLGtkPaintContext()'' class constructor with the newly
allocated memory pointer as its first argument. (NOTE: In C++, the first
argument of any class method is always the address of the current object,
denoted by the keyword ''this''.)
Now that we know the ''ZLGtkPaintContext'' class uses overall 0xc8 bytes, and
the last initialized entry is at affset 0xc0 (which is ''DWORD'', or 4 bytes),
ww can perform simple algebra to determine how many potentially uninitialized
bytes are after ''rbx+0xc0'':
overall_size - last_rbx_offset + last_rbx_datatype_len =
= 0xc8 - 0xc0 + 4 =
= 4
Here is the table summarizing the intervals for the "missing" offsets:
...
QWORD PTR [rbx+0x70],rax ; 'rax' was set by the call
QWORD PTR [rbx+0xb8],0xffffffffffffffff
Rewrites could look like this:
--------------------------[ patch_protoype_01.nasm ]---------------------------
xor eax, eax ; zero out RAX
mov QWORD [rbx+0x08], rax ; offset 0x08-0x10
mov QWORD [rbx+0x10], rax ; offset 0x10-0x18
mov QWORD [rbx+0x18], rax ; offset 0x18-0x20
mov QWORD [rbx+0x40], rax ; offset 0x40-0x48
mov QWORD [rbx+0x50], rax ; offset 0x50-0x58
mov QWORD [rbx+0x58], rax ; offset 0x58-0x60 <-- [1]
; call 197f0
; WORD PTR [rbx+0x88],ax
xor eax, eax ; zero out RAX again, it might contain a value
mov DWORD [rbx+0x8a], rax ; offset 0x8a-0x90 <-- [2]
mov QWORD [rbx+0xc0], rax ; offset 0xc0-0xc8 <-- [1]
-------------------------------------------------------------------------------
In certain situations, we can combine multiple values into a single instruction
that utilizes a large bit range, as demonstrated in [1]. However, in some
cases, like in [2], we need be careful, and avoid writing memory before it
(''[rbx+0x88]'') because it holds the return value of a function (''ax'').
And we can take it even further by leveraging features of the x86 instruction
set and the original code to our advantage. We could prototype a kind of loop
that will effectively zero out the entire allocated memory. The only concern we
should have is ensuring that we avoid those non-zero assignments we previously
discovered.
I have something like this in mind:
--------------------------[ patch_protoype_02.nasm ]---------------------------
BITS 64
push rcx ; Save all registers we are working with
push rdi
push rax
mov ecx, 0xc0 / 8 ; Counter: size of memory divided by QWORD length
xor eax, eax ; Zero out RAX, we'll use it as the zero value
mov rdi, rbx ; RDI is a memory pointer 'stosq' is writing to
rep stosq ; Rewrite memory at 'RDI+RCX' with value of 'RAX'
pop rax ; Restore all registers we where working with
pop rdi
pop rcx
-------------------------------------------------------------------------------
NOTE: ''stosq'' stores quadword from RAX at address RDI [ref14] (in our
example, this means 8 bytes of zeroes). ''rep'' is an instruction prefix that
repeats a string instruction the number of times specified in RCX (''rep'' can
be used only with specific instructions -- see [ref15]).
When built, the binary code has a size of 19 bytes:
$ nasm -O 0 -f bin patch_protoype_01.nasm -o patch_protoype_01
$ wc -c < a.bin
19
However, this isn't good enough for me. I'd like to place it near the beginning
(specifically at the address ''26ba0''), so that it doesn't overwrite the later
assignments. The code I want to replace is:
26ba0: c6 83 8a 00 00 00 00 mov BYTE PTR [rbx+0x8a],0x0
26ba7: 48 c7 83 a0 00 00 00 mov QWORD PTR [rbx+0xa0],0x0
26bae: 00 00 00 00
Unfortunately, these instructions together take up 18 bytes in total. Since our
prototype code has an extra byte, we would actually be overflowing. This cannot
happen!
There are two widely used techniques to optimize the size of a binary:
1. Using smaller opcodes. For example, the instruction ''mov ecx, 0xc0 / 8'' is
represented as ''B918000000'' in binary and occupies 5 bytes. Paradoxically, by
splitting it into two instructions, we can make it more compact: ''xor ecx,ecx;
mov cl,0xc0 / 8'', which results in the binary code ''31c9b118''. And there we
have the one byte we need.
2. Oooor we can exploit the code to our advantage by identifying and removing
any unnecessary instructions that are not used within the function. For
instance, ''rdi'' is a callee-saved register that is only used once at the
beginning, where its value is stored into ''rbx'', which serves as the ''this''
pointer. In this case, we can eliminate at least these three instructions:
push rdi ; no need to save it, it's not used
pop rdi ; and no need to restore it either
mov rdi, rbx ; moreover, RDI has the same value as RBX
Optimized code would look like this:
--------------------------[ patch_protoype_02.nasm ]---------------------------
BITS 64
push rcx ; Save all registers we are working with
push rax
mov ecx, 0xc0 / 8 ; Allocated memory divided by QWORD length
xor eax, eax ; Zero out RAX as we'll use it as the value
rep stosq ; Rewrite memory at 'rdi+rcx' with the value in 'rax'.
pop rax ; Restore all registers we where working with
pop rcx
-------------------------------------------------------------------------------
Now it has only 14 bytes:
$ nasm -O 0 -f bin patch_protoype_02.nasm -o patch_protoype_02
$ wc -c < patch_protoype_02
14
This is cool, but now it's way too small (or still not small enough), so we
have to pad the rest. There are ''18 - 14 = 4'' bytes to pad. We could use four
''nop'' instructions and be done with it, buuuut there are multi-byte NOP
instructions [ref16] that can also be used. Unfortunately, NASM doesn't
properly support them, therefore we need to create a correct sequence of bytes:
db 0x0F, 0x1F, 0x40, 0x00
(I won't deny it, this code does look much 1337er!)
I would likely attempt to further optimize it or simply go with the first
technique and create an 18-byte-sized binary code, but playtime's over! Let's
patch!
===[ Patching ]~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
It's time to roll up our sleeves and get started. We don't need any fancy tools
to get the job done. Patching can be accomplished with just "good" old ''dd''
[ref17].
We'll need to be precise here. In addition to rewriting bytes at the correct
offset and rewriting only 18 bytes, we must also ensure that the file isn't
truncated. ''dd'' is a very useful tool, but it's definitely not the most
user-friendly. (No wonder, it's from 1974 [ref18].)
Rewriting bytes on the exact position using ''dd'' can be tricky. The
old-school approach is to set the output block size (''obs'') to 1, which seeks
to the correct position but writes input one byte at a time (i.e., for every
byte, the ''write(2)'' syscall is called). While this approach is inefficient,
it's negligible for small inputs. Newer versions of ''dd'' offer the "byte"
suffix (''B'') for seek/skip options, allowing us to write commands like:
''dd if=i of=o skip=7B'' without sacrificing block size.
Let's take ''patch_protoype_01.nasm'' and craft the final code that we will
inject:
------------------------------[ inject_me.nasm ]-------------------------------
BITS 64
push rcx ; Save all registers we are working with
push rax
mov ecx, 0xc0 / 8 ; Allocated memory divided by the QWORD length
xor eax, eax ; Zero out RAX, we'll use it as the zero value
rep stosq ; Rewrite memory at RDI+RCX with the value in RAX
pop rax ; Restore all registers we where working with
pop rcx
db 0x0F, 0x1F, 0x40, 0x00 ; 4-byte NOP
-------------------------------------------------------------------------------
Build it:
$ nasm -O 0 -f bin inject_me.nasm -o inject_me
$ xxd -ps inject_me
5150b9c000000031c0f348ab58590f1f4000
$ wc -c < inject_me
18
And finally, let's inject the binary patch into the library at the offset
''0x26ba0'':
$ cp -a /usr/lib/zlibrary/ui/zlui-gtk.so .
$ dd if=inject_me of=zlui-gtk.so seek=$((0x26ba0)) obs=1 conv=notrunc
NOTE: The ''$((...))'' construct is shell math evaluation. which allows for the
quick conversion of hexadecimal numbers to decimal values and computation of
offsets on-the-fly, eliminating the need to evaluating it beforehand.
After patching, we should always verify that the resulting binary looks
correct:
$ objdump -M intel --disassemble='ZLGtkPaintContext::ZLGtkPaintContext()' \
--demangle ./zlui-gtk.so
...
26b99: 48 8b 05 68 03 01 00 mov rax,QWORD PTR [rip+0x10368]
26ba0: 51 push rcx
26ba1: 50 push rax
26ba2: b9 c0 00 00 00 mov ecx,0xc0
26ba7: 31 c0 xor eax,eax
26ba9: f3 48 ab rep stos QWORD PTR es:[rdi],rax
26bac: 58 pop rax
26bad: 59 pop rcx
26bae: 0f 1f 40 00 nop DWORD PTR [rax+0x0]
26bb2: 48 83 c0 10 add rax,0x10
...
Oh yeah! Everything looks good. Before we run our test, we need to replace the
original ''/usr/lib/zlibrary/ui/zlui-gtk.so'' with the modified one. Setting
''LD_LIBRARY_PATH'' has no effect because the path to the plugins is hardcoded
into the binary. (Try searching for the ''/usr/lib'' pattern within the
''/usr/lib/libzlcore.so'' library, and then use objdump to find the resulting
offset. You might see something like ''movabs rax,0x62696c2f7273752f'', which
represents the ''/usr/lib'' string in big-endian hexadecimal format, followed
by the loading of the ''/zlibrary/ui'' string from the ''.data'' section.)
# mv /usr/lib/zlibrary/ui/zlui-gtk.so /usr/lib/zlibrary/ui/zlui-gtk.so.OLD
# cp -a zlui-gtk.so /usr/lib/zlibrary/ui/zlui-gtk.so
$ fbreader bpf_performance_tools.epub
 Yay! It works as it should! :).
===[ Conclusion ]~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Reverse engineering, hacking, and modding are incredibly fun! It gives you the
power to manipulate any code you run. If it seems intimidating at first, don't
worry -- there's no need to be afraid. As you work through the problem, any
gaps in your knowledge will naturally fill in as you acquire new information.
The process is similar to solving a jigsaw puzzle: daunting at first, but with
each piece falling into place, the big picture emerges.
When starting, make it easy on yourself and choose a project with available
source code. This way, when assembly, binary, or memory contents don't make
sense, you can always refer back to the original code and gain insight into its
goals and how the compiler translates it.
For example, in this case study, it wasn't necessary to have the source code,
nor was it important to know that the ''myAnalysis'' structure actually comes
from the Pango library [ref19], since the patch was very straightforward.
However, having a reference point is still helpful, as some compiler
optimizations will inevitably obscure the binary.
One final thing: objdump is excellent for quick RE. I typically start radare2
or Ghidra for more complex tasks, as they can be overkill for simple cases
(esp. Ghidra). However, most of the time, it's sufficient and way faster to use
objdump (in conjunction with grep). Btw, since 2020-01-13, objdump has the
''--visualize-jumps'' parameter that generates ASCII art diagrams showing the
destinations of flow control instructions [ref20]:
$ objdump --visualize-jumps /lib/x86_64-linux-gnu/libc.so.6 | less
...
3583b: 48 85 ff test %rdi,%rdi
3583e: /-- 74 05 je 35845
35840: | 80 3f 00 cmpb $0x0,(%rdi)
35843: /--|-- 75 0b jne 35850
35845: | \-> 48 83 c4 18 add $0x18,%rsp
35849: | c3 ret
3584a: | 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
35850: \----> 48 8d 74 24 08 lea 0x8(%rsp),%rsi
35855: 31 d2 xor %edx,%edx
...
Unfortunately, it doesn't work well without symbols. radare2 and Ghidra are
still better for that job.
===[ References ]~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
> [ref1] https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=965379
* Bug#965379: FBreader: Sometimes draws hyphens after each word
> [ref2] https://lists.debian.org/debian-qa-packages/2022/02/msg00074.html
* FBreader source code patch.
* Siarhei Abmiotka
> [ref3] https://refspecs.linuxbase.org/elf/elf.pdf
> [ref4] http://www.sco.com/developers/devspecs/gabi41.pdf
> [ref5] https://man7.org/linux/man-pages/man5/elf.5.html
> [ref6] https://sourceware.org/binutils/docs/binutils.html#objdump
> [ref7] https://itanium-cxx-abi.github.io/cxx-abi/abi.html#mangling
> [ref8] https://www.stroustrup.com/arm.html
* Annotated C++ Reference Manual (1990): 7.2.1c
* Margaret A. Ellis, Bjarne Stroustrup
> [ref9] https://en.wikipedia.org/wiki/Name_mangling#How_different_compilers_mangle_the_same_functions
> [ref10] https://www.man7.org/linux/man-pages/man3/dlopen.3.html
> [ref11] https://security-tracker.debian.org/tracker/CVE-2008-0166
> [ref12] https://lists.debian.org/debian-security-announce/2008/msg00152.html
* [SECURITY] [DSA 1571-1] New openssl packages fix predictable random number generator
> [ref13] https://en.wikipedia.org/wiki/Trampoline_(computing)
> [ref14] https://www.felixcloutier.com/x86/stos:stosb:stosw:stosd:stosq
> [ref15] https://www.felixcloutier.com/x86/rep:repe:repz:repne:repnz
> [ref16] https://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-optimization-manual.pdf
* 3.5.1.9 Using NOPs
* April 2024 ; Document Number: 248966-050US
> [ref17] https://www.man7.org/linux/man-pages/man1/dd.1.html
> [ref18] https://en.wikipedia.org/wiki/Dd_(Unix)
> [ref19] https://docs.gtk.org/Pango/struct.Analysis.html
> [ref20] https://sourceware.org/git/?p=binutils-gdb.git;a=commitdiff;h=1d67fe3b6e696fccb902d9919b9e58b7299a3205;hp=a4f2b7c5d931f2aa27851b59ae5817a6ee43cfcb
> [ref21] https://en.wikipedia.org/wiki/Name_mangling#Standardized_name_mangling_in_C++
Yay! It works as it should! :).
===[ Conclusion ]~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Reverse engineering, hacking, and modding are incredibly fun! It gives you the
power to manipulate any code you run. If it seems intimidating at first, don't
worry -- there's no need to be afraid. As you work through the problem, any
gaps in your knowledge will naturally fill in as you acquire new information.
The process is similar to solving a jigsaw puzzle: daunting at first, but with
each piece falling into place, the big picture emerges.
When starting, make it easy on yourself and choose a project with available
source code. This way, when assembly, binary, or memory contents don't make
sense, you can always refer back to the original code and gain insight into its
goals and how the compiler translates it.
For example, in this case study, it wasn't necessary to have the source code,
nor was it important to know that the ''myAnalysis'' structure actually comes
from the Pango library [ref19], since the patch was very straightforward.
However, having a reference point is still helpful, as some compiler
optimizations will inevitably obscure the binary.
One final thing: objdump is excellent for quick RE. I typically start radare2
or Ghidra for more complex tasks, as they can be overkill for simple cases
(esp. Ghidra). However, most of the time, it's sufficient and way faster to use
objdump (in conjunction with grep). Btw, since 2020-01-13, objdump has the
''--visualize-jumps'' parameter that generates ASCII art diagrams showing the
destinations of flow control instructions [ref20]:
$ objdump --visualize-jumps /lib/x86_64-linux-gnu/libc.so.6 | less
...
3583b: 48 85 ff test %rdi,%rdi
3583e: /-- 74 05 je 35845
35840: | 80 3f 00 cmpb $0x0,(%rdi)
35843: /--|-- 75 0b jne 35850
35845: | \-> 48 83 c4 18 add $0x18,%rsp
35849: | c3 ret
3584a: | 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
35850: \----> 48 8d 74 24 08 lea 0x8(%rsp),%rsi
35855: 31 d2 xor %edx,%edx
...
Unfortunately, it doesn't work well without symbols. radare2 and Ghidra are
still better for that job.
===[ References ]~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
> [ref1] https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=965379
* Bug#965379: FBreader: Sometimes draws hyphens after each word
> [ref2] https://lists.debian.org/debian-qa-packages/2022/02/msg00074.html
* FBreader source code patch.
* Siarhei Abmiotka
> [ref3] https://refspecs.linuxbase.org/elf/elf.pdf
> [ref4] http://www.sco.com/developers/devspecs/gabi41.pdf
> [ref5] https://man7.org/linux/man-pages/man5/elf.5.html
> [ref6] https://sourceware.org/binutils/docs/binutils.html#objdump
> [ref7] https://itanium-cxx-abi.github.io/cxx-abi/abi.html#mangling
> [ref8] https://www.stroustrup.com/arm.html
* Annotated C++ Reference Manual (1990): 7.2.1c
* Margaret A. Ellis, Bjarne Stroustrup
> [ref9] https://en.wikipedia.org/wiki/Name_mangling#How_different_compilers_mangle_the_same_functions
> [ref10] https://www.man7.org/linux/man-pages/man3/dlopen.3.html
> [ref11] https://security-tracker.debian.org/tracker/CVE-2008-0166
> [ref12] https://lists.debian.org/debian-security-announce/2008/msg00152.html
* [SECURITY] [DSA 1571-1] New openssl packages fix predictable random number generator
> [ref13] https://en.wikipedia.org/wiki/Trampoline_(computing)
> [ref14] https://www.felixcloutier.com/x86/stos:stosb:stosw:stosd:stosq
> [ref15] https://www.felixcloutier.com/x86/rep:repe:repz:repne:repnz
> [ref16] https://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-optimization-manual.pdf
* 3.5.1.9 Using NOPs
* April 2024 ; Document Number: 248966-050US
> [ref17] https://www.man7.org/linux/man-pages/man1/dd.1.html
> [ref18] https://en.wikipedia.org/wiki/Dd_(Unix)
> [ref19] https://docs.gtk.org/Pango/struct.Analysis.html
> [ref20] https://sourceware.org/git/?p=binutils-gdb.git;a=commitdiff;h=1d67fe3b6e696fccb902d9919b9e58b7299a3205;hp=a4f2b7c5d931f2aa27851b59ae5817a6ee43cfcb
> [ref21] https://en.wikipedia.org/wiki/Name_mangling#Standardized_name_mangling_in_C++